【生成AI導入にうってつけ】AWS製の生成AIアプリ&環境がメリットだらけだったので紹介してみる【aws-samples・generative-ai-use-cases-jp】
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
新規事業部 生成AIチーム 山本です。
生成AIが盛り上がっており、お客様と話す中でも生成AIを導入して試してみたいというお話をよくお聞きします。例えば、以下のようなケースです。
- どんなことができるのか(ユースケースを)知りたい
- 社内で使い始めたい
- (場合によっては)簡単なデモンストレーションを行いたい
ただ、以下のような課題や懸念点があるケースが多いです。
- 環境を用意するのが大変
- データを外部サービスや海外に出したくない
- 導入しても使われることが少ない
- サービスを作り込むのが大変
- 一度作るのは良いけど、その後の開発では別途作り直さないといけないので、その後の開発コストがかかりそう
この記事では、こうした課題や懸念点を解決できる環境として、AWS製のリポジトリであるaws-samples/generative-ai-use-cases-jpを紹介します。リンク先のページで使い方などがとても親切に書かれていますが、改めてこのリポジトリのメリットや適している場面や、まず使いたいという場合の注意点、データを外に出さないデプロイの仕方について記載します。
※ 本記事の画像やコードは、リンク先のものや、デプロイした後のサービス画面を引用しています
※ この記事は2023/12/06時点の内容です
generative-ai-use-cases-jp
リンクはこちらです
https://github.com/aws-samples/generative-ai-use-cases-jp/
概要
このリポジトリを利用することで、Webサービスを立ち上げることができます。このサービスでは、生成AIを使ってどのようなことができるか把握できる、ユースケースを体験できます。自社の(自分の)AWSアカウントにデプロイでき、AWSのサービスのみを使って構成されています。日本語で使うように特化されていて、導入後すぐに使うことが可能です。
言語モデルのユースケースだけでなく、画像生成・音声認識のユースケースも用意されています。

誰に向いているか
後述のようなメリットがあり、以下のような人・グループ・会社に向いていると思われます。
- 生成AIを導入して、試したい・把握したい
- 今後、生成AIの利用を拡大したい
- 生成AIのアプリを作りたい、参考となるアーキテクチャが知りたい
メリット・いいところ
メリットとして以下のような点があります。
メリット1:デプロイが簡単
コマンド数回でデプロイ可能です。デプロイ方法は動画でも解説されているので、エンジニアじゃない方でもデプロイできます。また、動画で紹介されている方法のように、AWSのCloud9というサービス内から実行すれば、開発環境の準備(ソフトウェアのインストール)も不要です。細かい設定も解説されています。
https://github.com/aws-samples/generative-ai-use-cases-jp/?tab=readme-ov-file#デプロイオプション
詳しい手順は後述の「使い方・機能」をご覧ください
メリット2:情報・データが社内環境の中で収まる(外にでない)
前述の通り、自社のAWSアカウントに環境をデプロイでき、AWS以外のサービスは使われていません。また、生成AIサービスのBedrockでは、使用データが学習に使われないことが明言されており、使用するデータは社内環境に留められると考えられます。
Amazon Bedrock では、お客様のコンテンツがベースモデルの向上に使用されたり、サードパーティのモデルプロバイダーと共有されたりすることはありません。
もう1つ気になる点として、海外にデータが出ないか、という点ですが、AWSのリソースをデプロイする先は東京リージョンを選択でき、海外リージョンを使用することなく構築できます。そのため、海外にデータが出ることなく使用できると考えられます。
※ 東京リージョンのみで構成するには、デプロイ時に以下の点を変更する必要があります(この方法で設定すれば、東京リージョンのみで構成可能です)。詳細なデプロイ手順は後述の「使い方」の章で述べます。
- Bedrockがデフォルトは海外リージョンのものが使用されるようになっています。デプロイ時のコマンドのオプションで東京リージョンを指定することで解消できます
- リクエスト元のIPアドレスを制限する設定を有効にすると、WAFが使用されるようになっています。デフォルトでは無効なので、何かオプションを指定するなどの操作は必要ありませんが、注意が必要です
(サンプルのデータで試すケースや、情報管理のポリシーがこの点を気にしないようであれば、この点は気にしなくて良いかと思います)
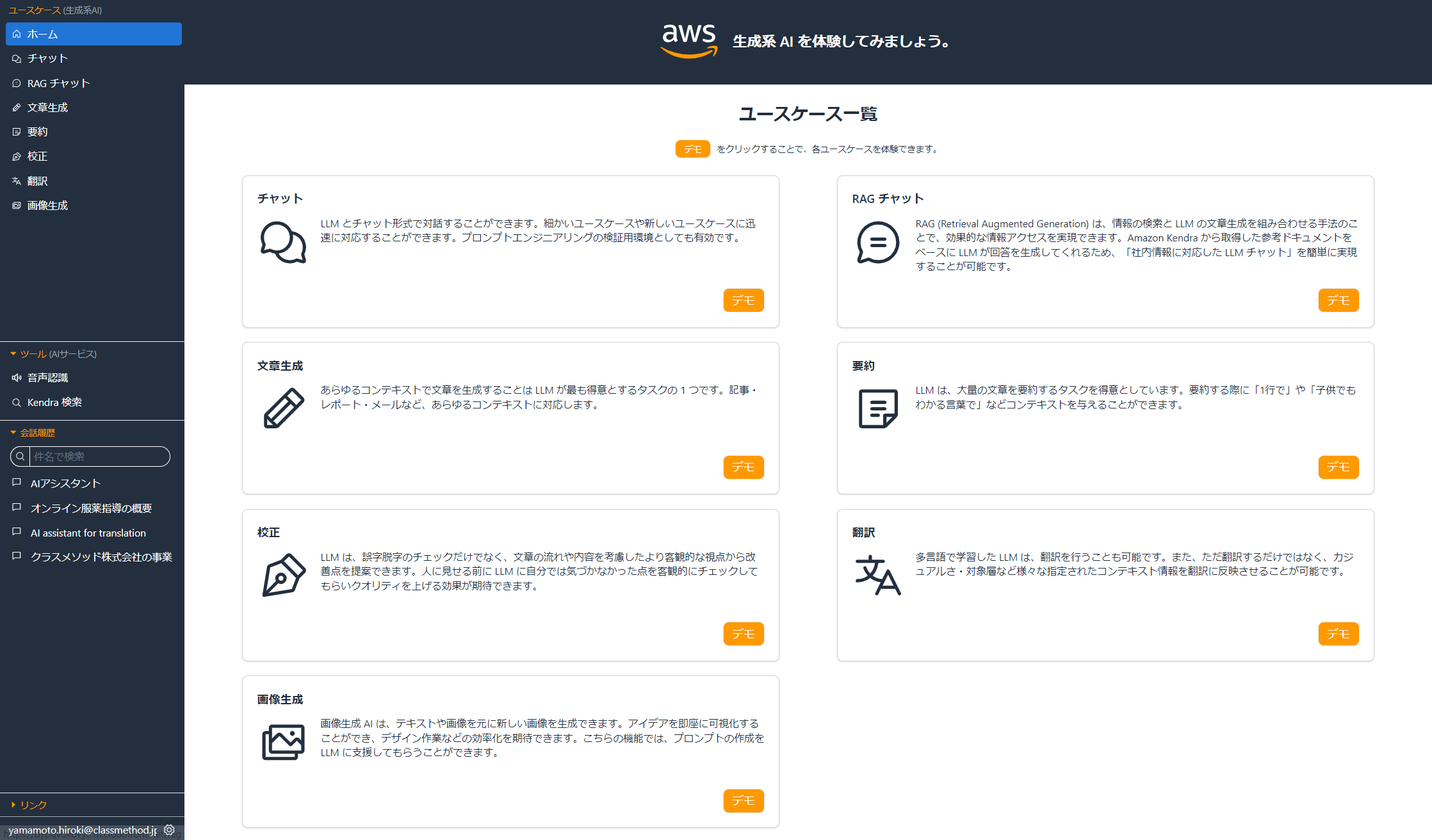
メリット3:ユースケースごとに分かれている・UIが用意されている
サービスにWebブラウザでアクセスしてサインインすると、ホーム画面が開かれますが、その時点でメニューが並べられており、何ができるか視覚的に把握できるようになっています。単なるチャット画面だけだと、何ができるのか・どういう使い方ができるのか、いまいちピンと来ない、というユーザもいますが、こうして用途が並べられていると、生成AIで何ができるのかが一目で把握でき、使用が促進されると思われます。
また、それぞれのユースケースで専用のUIが用意されており、設定項目がわかりやすく、生成AIを実行結果も見やすい形で表示されます。
具体的な動作はGif動画でも用意されているので、こちら見ていただければイメージが掴みやすいと思います
https://github.com/aws-samples/generative-ai-use-cases-jp/?tab=readme-ov-file#ユースケース一覧

UIの例:画像生成ユースケースの場合、元画像のアップローダやパラメータのスライダも用意されています
メリット4:機能が豊富・使いやすい
全体的に使いやすい構成になっていて、AWSでWebアプリを作るならこうするだろうな、という機能・構成になっている印象です。また、生成AIアプリとしても高いレベルの機能が用意されています。

フロントエンド
フロントエンドやUI部分は、初期のPoCや機能検証だと後回しにされたり、簡単なもので済ましがちです(それがネックで、PoCでは用意しない・簡易なもので済ませるケースもよくお聞きします)。このリポジトリでは、「メリット3」のようにUIが用意されており、構成も以下のようになっています。
- S3での静的ホスティング
- Cloudfrontを使ったCDNによるコンテンツ配信
- web用のファイルは、React・TypeScriptで書かれいて扱いやすい
(あまりフロントエンドに詳しくないので、間違っていたら申し訳ありません)
バックエンド(API部分)
バックエンドで使われているAWSサービスも、すべてサーバレスサービス・マネージドサービスで構成されているため、運用や管理もしやすく料金も安いです。
- API GatewayによるREST APIの提供
- Lambdaでのマイクロサービスなアーキテクチャ
(補足:上の構成図では、Lambdaが大きく書かれていますが、実際には小さいLambda関数が複数あり、APIのメソッドごとに別の関数を呼び出す形になっています。それぞれに対応するファイルも分かれており、該当する部分がわかりやすいです)
認証
セキュリティ・認証機能も用意されています。セキュリティ部分は手間&慎重になる必要があって時間がかかりがちですが、用意されているとすぐに開始できるのですごく助かります。以下のサービス設定がされています。
- WAFによるリクエストIPアドレス(※ 前述のとおり、WAFを使うよう設定した場合、海外リージョンで構築されます)
- Cognitoでのユーザ認証
LLMの体験(生成AIアプリの機能)
生成AIアプリとしてもほぼ最新レベルの機能があるように感じました。AWSサービスとしては、以下のようになっています
- DynamoDBで会話履歴管理
- Bedrockで最新のLLMを使用でき、モデルを切り替えることも可能。
- KendraによるRAG(Retrieval Augmented Generation)を使った会話が可能
アプリとしても、プロンプトは指示が細かく書いてあり(凝られていて)Claude用に適した形で書かれています(とても参考になるレベルです)。LLMアプリを自作すると、単純な一問一答しか実装しないことが多いですが、このアプリでは会話履歴も考慮できるようになっているようです。
「RAGチャット」では、直接ユーザの入力テキストで検索するのではなく、前処理を挟んでKendraに検索するための文章(クエリ)をLLMに考える機能も入っています。ドキュメントのデータソースとして、RAG部分はデフォルトではAWSのBedrockの解説ページをWebCrawlerで取得するものが使われますが、設定ファイルを1行書き換えれば、自分で立ち上げたKendraを使うように設定できます。なので、例えば、自社のドキュメントをインポートしたインデックスを用意すれば、自社ドキュメントに関するQAを試せます。
(Kendraの料金が高いですが、使わない場合は利用料を節約できるように、設定ファイルを1箇所変更すればオン・オフが可能になっています)
※ 「RAGチャット」では会話履歴は考慮されないようです。packages/web/src/hooks/useRag.tsの33行目を見る限り、retrieveQueries: [content]となっていて、ユーザの直前に入力したテキストのみを渡す動作をしているように思われます。
const query = await predict({
messages: [
{
role: 'user',
content: ragPrompt({
promptType: 'RETRIEVE',
retrieveQueries: [content],
}),
},
],
});
// Kendra から 参考ドキュメントを Retrieve してシステムコンテキストとして設定する
const items = await retrieve(query);
updateSystemContext(
ragPrompt({
promptType: 'SYSTEM_CONTEXT',
referenceItems: items.data.ResultItems ?? [],
})
);
メリット5:機能追加開発が簡単
「メリット4」のようにサービス構成はわかりやすく、リポジトリ内部のファイル構成もわかりやすくなっています。なので、コードの現状を把握して機能を改修する、ということも、そこまで難しくなさそうです。機能追加=メニューにユースケースを追加する方法は、「参照」のリンク先で解説されています。
https://github.com/aws-samples/generative-ai-use-cases-jp/?tab=readme-ov-file#参照
修正するべきファイルがどれか、どのように変更すればいいか、まで書かれていてとても親切です。ここまで解説されていると、フレームワークやプログラミングの知識がそこまでなくても、ChatGPTやGithub Copilotを使いながら実装できそうなレベルかなと思います。(今後やってみたいと思っています(デプロイしたこのサービスの「チャット」で質問しても良いですね))
ライセンスはMITなので、特に制約・条件がなく改変・流用が可能で、商用利用可です。

なので、まずこのリポジトリで導入して試用し、結果が良ければこのリポジトリをベースに次の開発につなげていく、というプロジェクトの進め方だと、スピード感を持って取り組めるように思えました。
制約
強いてデメリットを挙げるとすると、AWS内のサービスのみで構成されているので、例えばOpenAI社のモデル(GPT-3.5-turboやGPT-4)を使いたい場合は、自分で実装を追加する必要があります。
また、何か別のサービスと連携させたい場合も、自分で実装を追加する必要があります。例えば、バックエンドのAPI部分を使ったSlackアプリを作りたいといったケースです。
使い方
とりあえず試したいという場合は、リポジトリに記載されている手順でデプロイ可能です。Cloud9だと環境の用意が不要なのでオススメです。そのままコマンドを実行するだけなので簡単です。
https://github.com/aws-samples/generative-ai-use-cases-jp/tree/main?tab=readme-ov-file#デプロイ
https://www.youtube.com/watch?v=9sMA17OKP1k&ab_channel=KazuhitoGo
ただ、以下の条件に当てはまる方は、次に記載する手順でデプロイするのがオススメです。(通常の場合とほとんど変わりませんが、一部設定項目を変更した状態でデプロイします)
- 日本リージョンのみを使いたい
- デプロイ開始時点から、社内の人のみが利用できる状態(社外の人が利用できない状態)にしておきたい
手順1:AWSリソースを構築する
※ 以下、AWSのマネジメントコンソールでの操作は、東京リージョンで行われていることを確認しながら行ってください。
手順1-1:Bedrockを有効化する
(既にお使いのアカウントの東京リージョンで有効化している場合は、この手順は不要です)
- AWSのマネジメントコンソールでBedrockにアクセスします
- 左側のペインでModel Accessを選択します
- オレンジ色の「Manage model access」ボタンを選択します

※ これは既に有効化されている状態です。有効化する前はすべてのモデルのAccesss statusが「Available to request」になっていました。
-
「Claude Instant」の左側のチェックボックスにチェックを入れ(他のモデルも使用する場合は、すべてにチェックを入れ)、注意事項を確認し、オレンジ色の「Save changes」ボタンを押します

手順1-2:CDKでリソースをデプロイする
今回はCloud9を使った手順を紹介します。手元のPCなどに既に環境が整っている場合はそちらから実行しても、もちろん問題ありません。基本的な操作は以下の動画がわかりやすいので、こちらをご参照ください
https://www.youtube.com/watch?v=9sMA17OKP1k&ab_channel=KazuhitoGo
- Cloud9の環境作成・権限設定
上の動画の0.00~2:57を参考に、Cloud9環境を作成し、IAMの権限設定、Cloud9の権限変更を行います。
-
npmモジュールのインストール
上の動画の2:57~3:17を参考に、リポジトリをクローンし、npmモジュールをインストールします
git clone https://github.com/aws-samples/generative-ai-use-cases-jp/ cd generative-ai-use-cases-jp npm ci
- AWS CLIの設定
少し動画と操作内容を変更します。
上の動画の3:17~3:36と同様ですが、指定するリージョン(Default region name)は、動画のものではなく「ap-northeast-1」を指定してください。
-
CDKのbootstrap
(お使いのアカウントのリージョンで、以前bootstrapを実行している場合はこの操作は不要です)
上の動画の3:36~3:57を参考に、cdkの初期化(bootstrap)を実行します
npx -w packages/cdk cdk bootstrap
- CDKのデプロイ
上の動画の3:57~4:25と同様ですが、以下のようにデプロイしてください
- 左のペインで「generative-ai-use-cases-jp/packages/cdk/cdk.json」を選択して、開いてください。selfSignUpEnabledのtrueを「false」に書き換えてください。ctrl+sで保存してください。また、IPアドレスの制限項目である、allowedIpV4AddressRanges・allowedIpV6AddressRangesはnullのままにしておいてください。
(RAGチャット機能を使用したい場合は、ragEnabledをtrueにしてください)

※ 誰でも自分でWebアプリに登録できてしまう機能(セルフサインアップ)をオフにするための設定です。詳細は後述の「注意点」の章をご覧ください。
-
この状態でターミナルのタブに切り替えて戻り、デプロイコマンドを実行します。このとき以下のようにオプションをつけてください。また、allowedIpV4AddressRanges・allowedIpV6AddressRangesはオプションとして設定しないでください。
npm run cdk:deploy -- -c modelRegion=ap-northeast-1 -c modelName=anthropic.claude-instant-v1 -c promptTemplate=claude.json
※ Bedrockのリージョンとして、東京リージョンを指定するための設定です。東京リージョンでは、Cloude V2がまだ利用できないため、claude-instant-v1を指定します。
-
ビルドが続いて数分経過した後、IAMの変更について確認されるので、yを押して進めます

-
(デプロイが終わるまで待ちます。早ければ10分程度、遅ければ30分程度かかります)
- 左のペインで「generative-ai-use-cases-jp/packages/cdk/cdk.json」を選択して、開いてください。selfSignUpEnabledのtrueを「false」に書き換えてください。ctrl+sで保存してください。また、IPアドレスの制限項目である、allowedIpV4AddressRanges・allowedIpV6AddressRangesはnullのままにしておいてください。
動作確認
CDKのデプロイが終わると、以下のようにデプロイ結果が表示されます。この内最後の行の「GenerativeAiUseCasesStack.WebUrl」に書かれた「https://~~~~~~~~.cloudfront.net」が、今回デプロイしたWebサービスのアドレスです。

このアドレスにアクセスし、以下のようにサインインの画面が表示されればOKです。

※ Cloud9を使用する場合、Cloud9の環境を作成してから削除するまでの間、Cloud9の環境を使用しなくても、EBSの料金が毎月かかります。具体的には、EBSで10GBのボリュームが作成されるため、0.96$=150円/月程度です。気になる場合は、Cloud9の環境はデプロイ後に削除してください。ただ、リポジトリの内容を修正して再度デプロイする、というような作業も今後行う可能性があることを考えると、都度環境を作成するのも手間だと思うので、残しておくと便利かと思います。
手順2:Cognitoでユーザを作成する
手順1-2でセルフサインアップを無効化したため、管理者がユーザを作成する(Webサービスに登録する)必要があります。方法としては、以下の2つを紹介します。人数に応じて変える方が楽かなと思います(必須ではありません、どちらの方法でも良いかと思います)
- ユーザが少人数の場合(管理者が時間を取れる場合)
- AWSのマネジメントコンソールにアクセスし、Cognitoのページに移動し、ユーザプールを表示します。この内AuthUserPoolで始まるものが、今回デプロイしたユーザプールですので、これを選択してください。

-
表示されるページの「ユーザー」の欄の「ユーザーを作成」を選択します

※この画像は既にユーザを作成した後の状態です。作成前は、ユーザ数が0で、ユーザ名の欄には何も表示されていませんでした。
-
以下のように設定します。ユーザに初期パスワードが書かれたメールを送信するという設定です(必要に応じて変更してください)。
- 招待メッセージ:「Eメールで招待を送信」を選択
- Eメールアドレス:招待したいユーザのメールアドレスを入力
- 仮パスワード:「パスワードの生成」を選択

-
ユーザが追加されます。これを人数分繰り返してください

- AWSのマネジメントコンソールにアクセスし、Cognitoのページに移動し、ユーザプールを表示します。この内AuthUserPoolで始まるものが、今回デプロイしたユーザプールですので、これを選択してください。
-
ユーザが大人数の場合(管理者が時間を取れない場合)
以下の手順でユーザを一気に作成します
- 登録するユーザのメールアドレスのリストを作成してください
- スクリプトを実行するための環境を用意してください(boto3とCognitoを操作する権限が必要です)。デプロイ時にCloud9を使った場合はそれでも構いません。以下はCloud9の操作を例に示します。
- フォルダを作成します。左ペインを右クリックするとメニューが開かれるので「New Folder」を選択してください。クローンしたリポジトリと同じ階層がおすすめです(リポジトリの中に作らないほうが良いかと思います)。名前は任意のもので構いませんが、今回は「tools」とした場合について記載します。

-
同様の操作で、toolsの中にファイルを2つ作成し、名前はlist.txtとregister.pyとしてください
-
list.txtを開き、登録したいユーザのメールアドレスを、改行しながら入力してください

-
register.pyを開き、以下の内容をコピペしてください。また、USER_POOL_IDは、CognitoのページからユーザプールIDをコピーし、書き換えてください。

import boto3 # Cognitoの設定 USER_POOL_ID = "ap-northeast-1_XXXXXXXXXXX" # ユーザープールのIDを設定 # Boto3 Cognito Identity Providerクライアントの初期化 client = boto3.client("cognito-idp", region_name="ap-northeast-1") # プロファイル名を設定(任意) def create_cognito_user(email): # ユーザーの作成(一時パスワードはAWSに生成させる) response = client.admin_create_user( UserPoolId=USER_POOL_ID, Username=email, UserAttributes=[{"Name": "email", "Value": email}], DesiredDeliveryMediums=["EMAIL"], ) return response # メイン関数 def main(): with open("list.txt", "r") as f: lines = f.readlines() emails_error = [] for line in lines: email = line.strip() if email == "": continue try: response = create_cognito_user(email) except Exception as e: print(f"ユーザーの作成に失敗しました。: {email}") emails_error.append(email) print(e) continue if response["ResponseMetadata"]["HTTPStatusCode"] == 200: print(f"ユーザーの作成に成功しました。: {email}") else: print(f"ユーザーの作成に失敗しました。: {email}") emails_error.append(email) if emails_error: print("作成に失敗したメールアドレス:") for email in emails_error: print(email) if __name__ == "__main__": main() - ターミナルを開き以下のコマンドを実行してください
pip install boto3 cd tools/ python register.py
※ スクリプトの動作検証などは行っていないので、気になる場合は内容をチェックしてから実行していただくようお願いします。
どちらのケースでも、ユーザはメールを受け取るので、書かれているURLにアクセスし、サインイン画面でメールアドレス(ユーザID)とメールにかかれている初期パスワードを入力することで、サービスにサインインして利用を開始できます(初回サインイン時のみパスワード変更が必要です)

補足
Cognitoには、サインアップ時にメールアドレスのドメインを制限する機能(例えば、〇〇@classmethod.jpのみ許可する)がデフォルトではありません(おそらく。あるようでしたらそちらを使うと楽かと思います)。この機能を付けるとしたら、サインアップ時にLambda関数を呼び出すように設定し、Lambda関数内でメールアドレスをチェックするコードを書き、それをCDKのリソースとしてくっつけるという修正が必要です。これができる場合はこちらが素直かなと思います。また、他の認証手段を使うというのもありです。
今回は、CDKの内容に変更を加えずに利用開始できる方法として、Cognitoでユーザを作成する手順を紹介しました。
注意点(詳細)
料金
RAG部分を使うと、Kendraというサービスが立ちあがり、これが10万円/月程度かかります。比較的高額で、利用しなくてもかかってしまいますので、ご注意ください。不要になったら、cdk.jsonでragEnabledをfalseにし、kendraIndexArnをnullにして、cdk:deployを実行してください(Bedrockで日本リージョンを使いたい場合はオプションをつけるのを忘れないでください)。
それ以外は料金が安いサービスが使われています。一番料金が高くなると予想されるのがBedrockですが、これも一回の利用あたり、画像生成が数十円程度、テキスト生成も高くて数十円程度です。なので、今回のような簡単に試してみる程度の使用量では、高くて数千円/月くらいの料金になると予想されます。
※ もちろん使用量に応じて料金が変わり、実際の料金とは異なりますので、ご注意ください。各サービスの料金については、AWSのページでご確認ください。
セキュリティ面
セルフサインインをtrueにしていると、もしそのWebサービスのURLが外部に漏れてしまったり、なにかしらの形でそのURLがわかってしまった場合、外部の人が自分でサインアップして、サービスを使えてしまいます。
元のリポジトリの内容から変更がなければ、Webサービスからは今回デプロイした内容以外は見えない(アカウント内部の他のサービスの情報が漏れるということはありません)が、勝手に使われて利用費が増えてしまう点が問題です。
なので、利用開始時点では、上記のようにセルフサインインはオフにしてデプロイし、管理者がCognitoでユーザを発行する方がオススメです。もしAWSの実装が可能なら、前述のとおり、CognitoからLambda関数を呼び出し、メールアドレスのドメインをチェックする方式がオススメです。
データ面
今回のリポジトリでは、以下の点が気をつけるポイントです
- IPアドレス制限を設定にしたらWAFが海外リージョンに構築されてしまう
- Bedrockはデフォルトだと海外リージョンのモデルを使ってしまう
WAFが海外リージョンにあると、ユーザのWebブラウザからのリクエストデータが海外に送信されることになります。ここが気になる場合はWAFを使わない構成にする必要があり、そのためにはIPアドレス制限を設定しない形で利用することになります。これは、前述の通り、cdk.jsonの「allowedIpV4AddressRanges」と「allowedIpV6AddressRanges」を「null」にしておき、cdkのデプロイコマンドに2つをオプションとして指定しなければ実現されます。
WAFを使用するかどうかの判定箇所は、packages/cdk/bin/generative-ai-use-cases.tsの20行目にかかれています。
const allowedIpV4AddressRanges: string[] | null = app.node.tryGetContext(
'allowedIpV4AddressRanges'
)!;
const allowedIpV6AddressRanges: string[] | null = app.node.tryGetContext(
'allowedIpV6AddressRanges'
)!;
let wafStack: WafStack | undefined;
if (allowedIpV4AddressRanges || allowedIpV6AddressRanges) {
// WAF v2 は us-east-1 でのみデプロイ可能なため、Stack を分けている
wafStack = new WafStack(app, 'WafStack', {
env: {
region: 'us-east-1',
},
allowedIpV4AddressRanges,
allowedIpV6AddressRanges,
});
}
Bedrockは、海外リージョンでないと最新のモデルを使えなくなります。現状東京リージョンではAnthropicのモデルとして、Claude Instant V1しか使えません。もしClaudeV2などを試したい場合は、リクエストの内容や使うデータを選びながら、海外リージョンを利用すると良さそうです。
※ 2023/12/07時点の内容です。開発が進んで内容や設定が変わる場合もありますので、このあたりにセンシティブな場合は、使用するコミットのバージョンやコードの内容をご確認ください。
現在も開発が進んでいる
このリポジトリは随時開発が進んでいます。
生成系AIの進化に伴い、破壊的な変更を加えることが多々あります。エラーが発生した際は、まず最初にmainブランチの更新がないかご確認ください。
と書かれているように、進化が早い分野で、開発もそれに追従しているため、変更点には注意が必要です。
まとめ
生成AIを試すWebアプリを簡単にデプロイできる、AWS製のリポジトリを紹介しました。
生成AIを導入したいという場面に適した、すごい良いものだと思いました。お客様と話す中で「まず社内で試したい、導入したい」というお話はよく聞き、それに当てはまるものだと思います。
全体的によく考えられていて、ユーザにも開発者にも優しいなという印象を持ちました。ユーザ管理の部分だけ少し手間ですが、Cognitoだと仕方ない部分かなというところで、今回ユーザ作成の手順を補足させていただきました。
メリットにも挙げたように、このリポジトリをもとにして、メニューを追加して社内サービスや自社サービスと連携するというやり方は、開発を進めている上で筋が良さそうです。









